
You’re not a tech whiz, but your company’s SEO still ends up on your lap in the marketing department. Working with an expert SEO agency to rise through the rankings and increase your web traffic is one route, but maybe your budget doesn’t support that just yet. Or maybe your boss needs to see results now, and you need some quick wins.
While you may not have the skills needed to gain substantial ground in search with fresh new tactics, you can definitely give your site the once-over to keep yourself out of the weeds. Check these technical SEO errors right now to ensure you aren’t hurting your search rankings and visibility online, and if you are, learn how to correct them.
SEO is a tricky concept to grasp at the best of times … But technical SEO is on a whole different level entirely!
Despite that, it really pays to spend time periodically brushing up on your knowledge.
Considering the complex nature of this topic, you’ll be glad to hear I’m going to keep you even more entertained, with the use of humorous GIFs!
The SEO space moves incredibly fast; new intricacies are constantly introduced and just one small mistake in your website code can potentially render your well-deserved organic visibility useless.
And by useless, I mean a seemingly “tiny” technical mistake could effectively ‘remove’ your website from Google results … no matter how much collective energy and investment you have dedicated to content marketing and link building.
A frightening situation, for sure — especially if your business relies on organic traffic to thrive. That’s why SEO is always a collaborative effort … anybody who has access to your website needs to be familiar with these potential blunders to avoid the consequences.
Here, we’re going to reveal three technical SEO errors that need your immediate investigation. Whether you’re a marketing director, CEO, entrepreneur or other professional — you (and your entire team) should know these disastrous technical SEO mistakes that can cost you and your business dearly.
Error #1: Unleashing the Single-Line Code of Doom
Level of Severity: High
We all make mistakes, but any errors made in one particular file will have serious outcomes. We’re talking about your .htaccess file. Just a single missed character or an extra space in this file can take your site down!
Before unveiling the ultimate mistake, here’s a little background info for you: If you’re using the Apache web server (which most currently are), fear not; military helicopters aren’t anywhere to be seen — but your .htaccess file can be considered the master command center of your website, your cockpit so to speak.
The next two most popular servers are NGINX and Microsoft-IIS, with NGINX rapidly becoming more widely-used. You can see the (historically) huge differences in usage here:
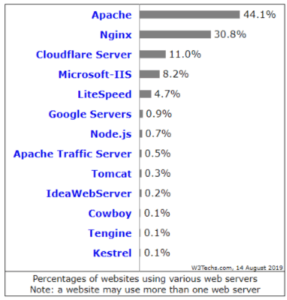
Just to make everything a tad more confusing; NGINX’s version of .htaccess is a file called nginx.conf, and Microsoft’s version is the web.config file. They are not like-for-like files, although they are comparable, with similar functions of master control.
Yikes — that’s a lot to wrap your head around.
Let’s break it down and see what you’re using.
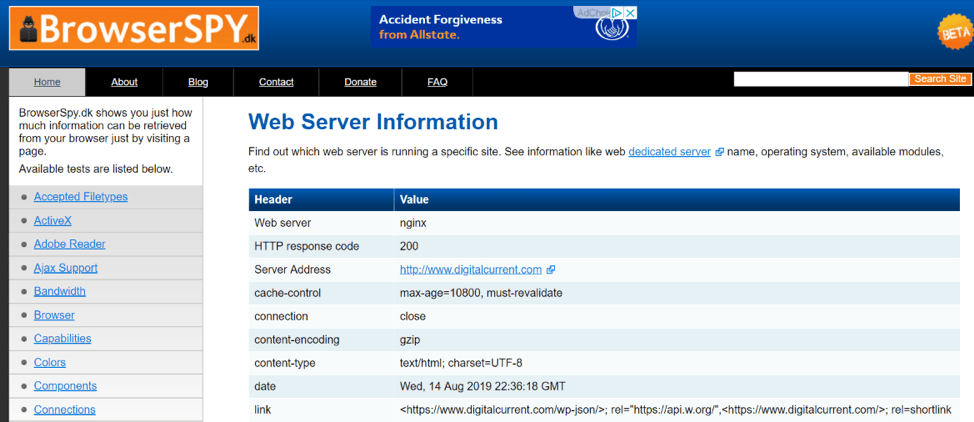
How do you know which server you are using?
You can do a quick search using this tool. Ta-da! Digital Current is using NGINX:
How do you reach your master control files?
You need to find and access these files via FTP (File Transfer Protocol) using FTP client software such as FileZilla. Of course, server-level login information is required. I recommend connecting using SFTP or FTPS to be extra secure.
You may need to pause here and get some credentials from your IT department. We’ll wait.
What’s the critical line of code to avoid?
Here’s the SEO-erroneous code for the two most popular servers, Apache and NGINX.
For Apache: If you have this line of code present in your .htaccess file, your website will not be included in search engine results!
Header set X-Robots-Tag “noindex, nofollow”
For NGINX: If you have this line of code present in your nginx.conf file, your website will also not be included in search engine results!
add_header X-Robots-Tag “noindex, nofollow”;
You can investigate the presence of these commands (known as HTTP headers) using this tool.
X-Robots directives are clever for tidy and efficient SEO. However, use them with extreme caution and ALWAYS ensure backups of your .htaccess (or other similar files) are maintained and checked after each and every website modification.
Sometimes, changes on the development version of your site can be pushed to live and these commands carelessly get carried over, too!
Put it this way … You really don’t want to be the one to make a mistake in your company’s master control file.
Always be aware of sudden traffic drops by creating custom intelligence alerts in Google Analytics.
Here are some more juicy .htaccess commands for your SEO experiments — and they can usually be translated in some way for NGINX and IIS users. Enjoy!
Error #2: Losing Control of Your URL Parameters
Level of Severity: Medium
URL is short for Uniform Resource Locator — just a fancy name for the web addresses of each page on the internet.
If you’re running an e-commerce website, a large news site or publisher site, you will likely have suffixes that begin with ‘/?’ and contain ‘=’ on a high number of URLs.
These suffixes are used to provide the same (or similar) page content in varied formats, i.e., sorted page content by highest price or most popular items. These are known as parameters.
They’re usually long, they’re always unsightly … and they can cause a bit of a mess!
- Such URL parameters can be declared in your Google Search Console via the ‘Crawl’ tab on the left-hand-side, directing Google to ignore the content on these duplicate pages and not waste crawl allocation doing so. However, this might waste authority gained from backlinks.
- Your robots.txt file can also direct search engines away from crawling these pages. If your parameter includes /?sort=order_popular you could use the below ‘wildcard’ directive to stop Google crawling this parameter plus all other parameters that display ‘/?’:
User-agent: *
Disallow: /?*
NOTE: This may not prevent other search engine spiders from crawling these URLs as wildcards (*) are not part of the standard robots.txt language.
Now, if these page variations have not yet acquired any links and other attention like social shares, they are not yet important for your organic visibility. In any case, they shouldn’t be included in search results.
It’s all about consolidation. Your entire website’s authority needs to be funneled for best organic performance.
If you have caught the culprit URLs in time (before they get famous) and now want to clean up these parameter strings that may have been indexed, here are some steps to take…
- Should you have a smaller site but still use parameters, you can then quickly remove all offending URLs from Google by using the Search Console ‘Remove URLs’ tool (although this is a manual process, one URL by one).
- Ensure your master pages (those without parameters) are easily found by search engines by declaring them in your .xml sitemap. As extra measures, use the ‘Allow’ directive in your robots.txt file (found at yourdomain.com/robots.txt) while also declaring your .xml sitemap there:
User-agent: *
Allow: /url-without-parameter/
Disallow: /url-with-parameter/?*
Sitemap: https://yourdomain.com/sitemap.xml
To ensure nothing slips through any cracks in such a scenario; you can use the “noindex, follow” meta robots tag on any URLs you don’t want to be indexed, while also applying the rel=”canonical” meta tag.
Applying the canonical tag tells Google which page is your master page for any set of duplicated URLs, while effectively funneling any collective ‘link juice’ to this master page.
<link rel=”canonical” href=”http://yourdomain.com/clean-url”>
You must use this tag on all dupe pages and the master page for it to work effectively. Of course, each URL demands an altered tag that matches.
If you have a large website, you should definitely implement dynamic canonical tags to somewhat automate the entire process.
NOTE 1: Directing Google not to crawl pages through robots.txt will most likely mean your meta robots and canonical tags on those pages aren’t acknowledged. However, robots.txt directives are not guaranteed to be followed — so in such a scenario, these tags act as a safety net.
NOTE 2: Crawl budget is said to only be an issue for huge websites or those with ‘infinite’ page results (e.g., dynamic calendars). So optionally, those with smaller sites can often be confident allowing all pages to be crawled, while utilizing either meta robots or X-Robots, plus canonical tags to hone link equity.
What if these parameter URLs have already gained some nice backlinks?
First, let’s walk through what you could do with a standard URL that you don’t want to be indexed (a URL without any parameters like ‘?’ after the first slash) in the scenario of it picking up valuable backlinks.
To check backlinks, use a tool like AHREFS.
You would omit this URL from being disallowed in robots.txt (so it can be crawled) and apply the previously mentioned “noindex, follow” page-level tag instead, also known as meta robots.
This is inserted into your page’s HTML <head> section:
<meta name=”robots” content=”noindex, follow” />
You would need to keep your canonical tags, too.
The above command is telling Google to pass earned ‘link juice’ on to other pages, but not to index this particular page in its search results.
You could then keep your house in order by removing the page from Google’s index, via Search Console.
Note: Before you do this — just ensure you have canonical tags in place and your desired master page is already indexed.
And solutions for parameter URLs?
This is where it can get a little tricky! Parameter URLs can be tougher to manipulate due to their dynamic nature (they typically aren’t ‘static’ pages).
Hold up — it’s not so bad!
When this is the case, it’s possible to maintain all authority passed from linking websites while preventing further unwanted attention to these parameter URLs — again, through the use of dynamically applied canonical tags and also via clever .htaccess commands to “noindex, follow” these pages.
Consequently, they will sooner or later drop out of Google’s index — but you can once more use the URL removal tool for priority pages, as a faster alternative.
NOTE: After the first half of this article, you will now be well aware of the delicate nature of the .htaccess file. Before you open it, always ensure you use a test environment that can easily be reverted. Never test on your live site!
Here’s another nice trick if you have a very large site that is eating up your crawl budget — and dynamic canonicals or .htaccess commands are causing too many headaches:
- Have your developers change the culprit parameter functions (and therefore, their accompanying URLs) that have gained a lot of juicy links, while redirecting the original parameter URLs to their standard, non-parameter URL counterparts.
Here’s an example:
Parameter URL that has gained valuable links:
www.yourdomain.com/hello/?sum=high
New parameter URL that provides the same (sorted) content:
www.yourdomain.com/hello/?sum=high_content
Original URL without any parameter:
www.yourdomain.com/hello/
Redirect this parameter:
www.yourdomain.com/hello/?sum=high
To the original URL:
www.yourdomain.com/hello/
301 redirects ensure you get to fully utilize the ‘link juice’ such parameter pages have earned — bringing you better chance of ranking your master pages in Google.
To keep it tidy, remove any traces of the original parameter URLs from your robots.txt file.
Once you’ve redirected as above, you can utilize robots.txt ‘Disallow’ commands on the new parameter URLs.
There, see — you’re getting it! Look at you go.
Note: It’s most favorable to block parameter URLs from being crawled via robots.txt if you have a large website or ‘infinite’ page results. Here’s some more info on optimizing your crawl budget. You can also keep an eye on undesirable spikes or drops in crawl rate via your Search Console ‘Crawl Stats’ tab:
Constantly track new backlinks and social shares of URLs. In the event of your new URLs picking up a high number of links, you can repeat all steps above.
Canonical and meta robots “noindex, follow” tags are however, usually the best primary action for relatively basic, smaller sites.
Always take time to weigh up the pros and cons before making any techy alterations. Should you make any complex changes for the sake of maximizing the benefit of one or two links? Probably not.
Should you make changes to funnel link equity gained from 125 powerful backlinks? YES.
This all helps rank your desired master pages, instead of diluting your website’s authority.
Error #3: Displaying Multiple Versions of Your Website
Level of Severity: High
This is one of the worst, yet most easily avoided mistakes we come across.
Did you know your website can have multiple versions, all live at the same time?
www.yourwebsite.com
yourwebsite.com
yourwebsite.com/index.html (on Apache)
https://yourwebsite.com
All four variations could show the same page and site!
Although the content would be exactly the same, search engines will see these domains as entirely separate websites — which can cause problems and conflict with indexation — not to mention confusion for users. You could also end up with all your ‘sites’ indexed and linked to from other domains.
Checks:
- First, ensure you select a preferred domain in Google Search Console.
- Check the listed domain variations above on your own domain, to see if they automatically redirect to your master domain URL.
- If they don’t: Houston, we may have a problem!
Actions:
- Ask your developers to set up 301 (permanent) redirects from all duplicate versions, if possible. (REMEMBER: All site pages must be matched and redirected to their counterparts, which can also be quickly achieved via .htaccess, if you have a large website).
- Most content management systems (CMS) such as WordPress will redirect uppercase URLs to lowercase, automatically. If this isn’t the case with your CMS, you can include special directives once again within our favorite file: The .htaccess!
- If it’s not possible to redirect URLs for whatever reason, I’d solely apply the canonical and “noindex, follow” tags where applicable, removing any indexed URLs in Google (using the URL removal tool via Search Console).
- Again, in this case — if duplicate domains and pages have already picked up good links, I would not apply the “nofollow” tag or “Disallow” directive in robots.txt — because the “SEO value” that has accumulated over time, may be lost.
- Also ensure all internal links on your preferred domain use same-domain links, not links pointing to another version of your site! It’s an easy mistake to make.
As a special extra, here are five more critical technical SEO checks for you to tick off:
BONUS: 5-Point Technical SEO Checklist
- MAXIMUM INDEXATION
- Search Google and check total indexed pages > site:yourdomain.com
- Check Search Console
- SMOOTH REDIRECTS
- Identify and rectify culprit redirect chains using this tool
(You should only have single redirects, from one page to another) - Check soft ‘302’ redirects using the tool above or this tool, then apply 301 redirects instead
(302 redirects are classed as temporary redirects and despite an overhaul in Google’s functioning, there has been speculation over how much ‘link juice’ they pass)
- Identify and rectify culprit redirect chains using this tool
- WATERTIGHT LINKS
- Identify broken links using Search Console, then apply 301 redirects to live pages
- RAPID SPEED
- Test pages using Google’s PageSpeed Insights tool
- Check server speed using Pingdom and GTmetrix
- MOBILE ELEGANCE
- Test pages using Google’s Mobile-Friendly tool
Visualise your website across many screen resolutions with Screenfly
You’re welcome! Yes, this could be huge.
But …
What’s Next?
If you’re still having trouble identifying or fixing technical SEO errors, it might be time to get in contact with a professional digital marketing agency.
